背景
合成音声が本を読んでくれる時代
僕は iPad の読み上げ機能 (Siri) をよく使います。本が尽きることはありませんから、コンスタントに良い体験ができています。合成音声最高!
特にピッチを下げて早回しにすると快適だったのでおすすめします。叩きつけるような喋り方は実質 Archspire です。ヘドバンが止まりません。
合成音声の使い道
合成音声は実況動画に使用されることが多いです。匿名性を保って情報共有できますし、ちょっとした実演にも向いているでしょう。
しかし編集コストは馬鹿になりません。たった 10 分の『ゆっくり実況』のために 10 時間も編集していれば、丸々一週間が潰れてしまいます。
より簡単な編集方法としては、まず実況動画を撮影し、後から合成音声に差し替えれば良いでしょう。やってみます。
デモ
AtCoder 実況動画を作ってみました:
編集時間は 1 時間程度です。文字起こしや字幕挿入はスクリプトから行いました。以降で方法を解説します。
使用ツール
Blender VSE
動画編集には Blender VSE (Video Sequence Editor) を使用します。起動画面にも Video Editing の文字が輝き、意外にも 3D モデリングツールの主要機能の 1 です。
スクリプティングのサポートが強力で、 Python から字幕や音声を挿入できます。今回の使用目的に最も合致したツールだったと思います。
Whisper
OpenAI の音声認識ソフトです。コマンドラインから音声ファイルの文字起こしができます。
複数の実装があります (whisper, faster-whisper, whisper-cpp, whisper-ctranslate) 。今回は whisper-cpp を使用しました。
RAM の大きな (> 10GB) GPU があれば、録音と同時に文字起こしができるようです。いい時代です。
VOICEVOX ENGINE
VOICEVOX ENGINE が読み上げのソフトウェアです。ずんだもん等で有名です。
実行するとローカルサーバが立ち上がるので、音声ファイル生成のリクエストを投げれば .wav ファイルが生成されます。これも簡単で良いですね。
ワークフロー
Blender VSE 入門
Blender VSE の初期画面は以下です。ゴタついています。
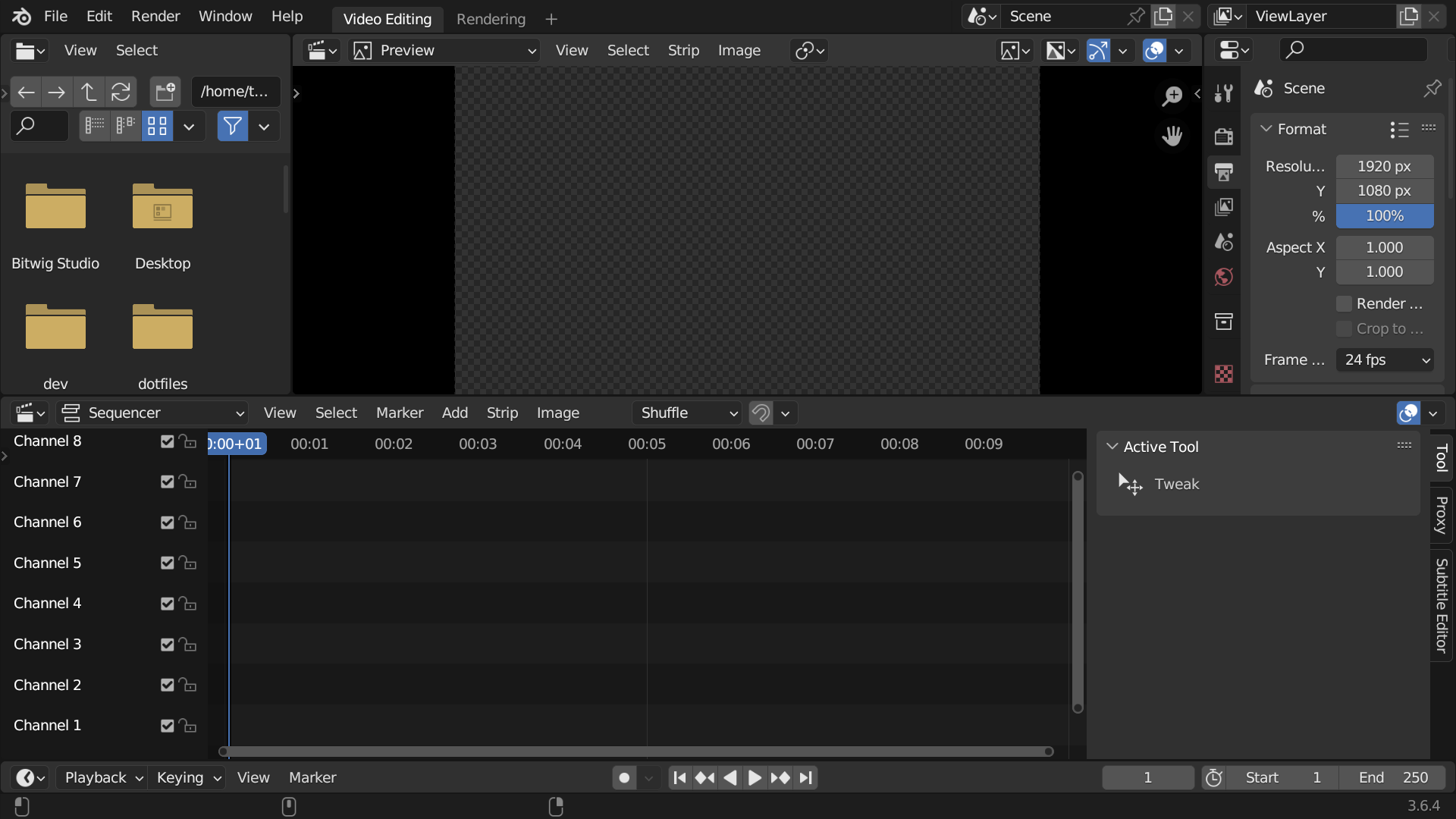
tin2tin 氏の Youtube に従って画面を調整します。上部画面を Sequencer & Preview 表示にして、ドラッグ操作を行えば次の通りです。
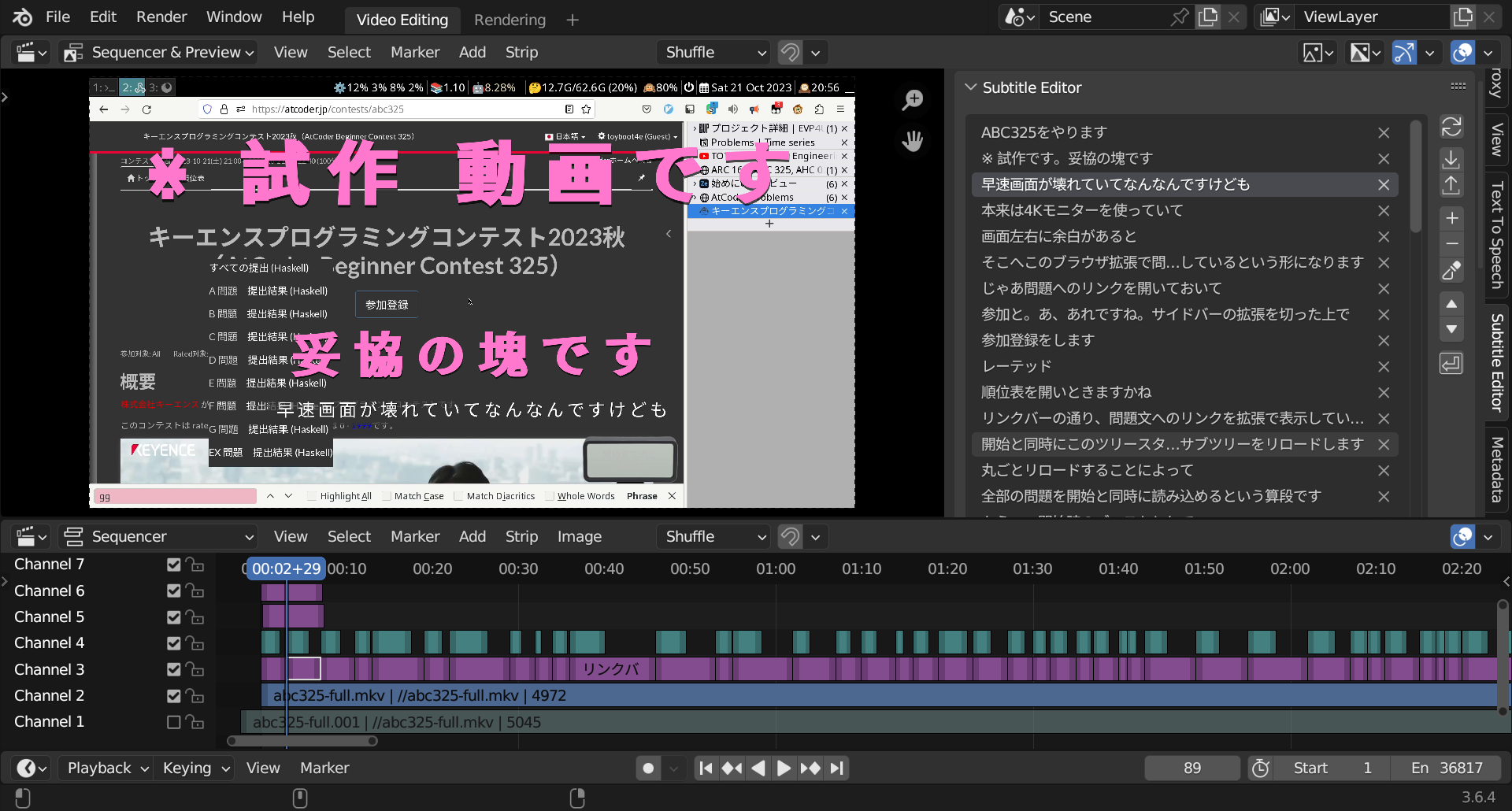
右上の字幕一覧は、同じく tin2tin 氏の Subtitle_Editor アドオンです。クリックで字幕の表示位置までジャンプしたり、文章も直接編集できます。課金したいレベルで良いです。
Whisper で文字起こし
whisper-cpp を使って実況動画を文字起こししました:
[00:00:00.000 --> 00:00:03.000] ABC325をやります
[00:00:03.000 --> 00:00:07.000] 早速画面が壊れてなんなんですけども字幕ファイル形式 (.srt) に変換すれば以下の通りです:
1
00:00:00,000 --> 00:00:03,000
ABC325をやります
2
00:00:03,000 --> 00:00:07,000
早速画面が壊れてなんなんですけどもこれを Blender で読み込めば、字幕が生成されます。後は音声を挿入するだけです。
whisper-cpp の呼び出し方は、次の記事を参考にしました: 作業ログ:音声認識の新時代・Whisper.cppの使用方法 - 虎(牛)龍未酉2.1 。
VOICEVOX ENGINE 入門
docker で VOICEVOX/voicevox_engine を起動します。
$ # CPU 版:
$ docker pull voicevox/voicevox_engine:nvidia-ubuntu20.04-latest
$ docker run --rm --gpus all -p '127.0.0.1:50021:50021' voicevox/voicevox_engine:nvidia-ubuntu20.04-latest起動後は http://127.0.0.1:50021/docs にアクセスできるようになり、 README の通り音声ファイルを生成できるようになります。音声ファイルの生成は Blender から行いましょう。
メモ: NixOS で GPU 版の起動失敗
enableNvidia オプションオプションも試しましたが効果無し。 NixOS 分からない……!
# Docker: <https://nixos.wiki/wiki/Docker>
virtualisation = {
docker = {
enable = true;
enableNvidia = true;
rootless = {
enable = true;
# $DOCKER_HOST
setSocketVariable = true;
};
};
};/etc/nixos/configuraton.nixBlender Python API
先駆者がいました! 助かりました。 BlenderでVOICEVOXの音声をPythonで追加 - Qiita
ターミナルから Blender を起動します。 Shift + F11 でスクリプトエディタを開き、 Python API (Sequence Editor, Sequence) を参考にスクリプトを書きます。
import bpy
# VSE (video sequence editor) を取得:
se = bpy.context.scene.sequence_editor
# 選択された字幕に対し
for s in filter(lambda s: s.select and s.type == 'TEXT', se.sequences_all):
# 文字内容や開始時間を表示する
print(s.text, s.frame_start, s.frame_duration)実行 (Alt-p) してみました。出力がターミナルに流れます:
Text 98.0 1字幕の文字内容や開始位置を取得できています。後は VOICEVOX ENGINE で音声ファイルを生成し、 se.new_sound で適切な位置に挿入します。実況動画の完成です。
課題
上のワークフローでは以下の問題が発生しました。
Whisper
読み上げ文章の 10% 程度は修正が必要でした。
- 同音異義語
『移す』と『写す』などで誤変換が現れました。 - 俗語や用語、固有名詞への対応が弱い
たとえば『競プロ』『Haskell』などは謎の言葉に置き換わりました。 - 英単語に弱い
accumarrayなど英語の関数名が謎の言葉に置き換わりました。
VOICEVOX
字幕と読みが一致しない場合があります。たとえば『word』を『ダブリューオーアールディー』と読んでしまいました。
Blender VSE
初期フォントだと中国語の字体になりました。まだ修正方法は探していません。
Unicode が字体を区別しないのは問題ですが、字体くらい変わってもコンテツは変わらないという気もします。
まとめ
Blender VSE + Whisper + VOICEVOX のワークフローを組み立てました。編集時間ゼロとは行きませんでしたが、簡素な動画なら編集の 90% を自動化できたと思います。
今後も実演動画を作る際には使っていくかもしれません。